|
你知道吗?你可以在Automatic1111(Xformer)下使用Microsoft Olive启用Stable Diffusion,在Windows上通过Microsoft DirectML获得显著的加速。微软和AMD一直在合作优化AMD硬件上的Olive路径,通过微软DirectML平台API和用于DirectML的AMD用户模式驱动程序的ML(机器学习)层加速,允许用户访问AMD GPU的AI(人工智能)功能。
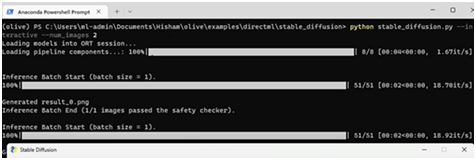
1.先决条件 •已安装Git(适用于Windows的Git) •已安装Anaconda/Miniconda(适用于Windows的Miniconda) o确保Anaconda/Miniconda目录已添加到PATH •具有AMD图形处理单元(GPU)的平台 o驱动程序:AMD软件:Adrenalin版 23.7.2或更新版本(https://www.amd.com/en/support) 2. Microsoft Olive概述 Microsoft Olive是一个Python工具,可用于转换、优化、量化和自动调整模型,以通过DirectML等ONNX Runtime执行提供程序获得最佳推理性能。Olive通过提供单一的工具链来组合优化技术,极大地简化了模型处理,这对于像Stable Diffusion这样对优化技术排序敏感的更复杂的模型尤其重要。Stable Diffusion的DirectML示例应用以下技术: •模型转换:将基本模型从PyTorch转换为ONNX。 •Transformer图优化:融合子图到多头注意力算子和消除转换效率低下。 •量化:将大多数层从FP32转换为FP16,以减少模型的GPU内存占用并提高性能。 综上所述,上述优化使DirectML能够利用AMD GPU,在使用Stable Diffusion等Transformer模型执行推理时,大大提高性能。 3.使用Microsoft Olive生成优化的Stable Diffusion模型 创建优化模型 (按照Olive的指示,我们可以使用Olive生成优化的Stable Diffusion模型) 1.打开Anaconda/Miniconda终端 2.通过在终端中依次输入以下命令,然后按enter键,创建一个新环境。需要注意的是,Python 3.9是必需的。 conda create --name olive python=3.9 conda activate olive pip install olive-ai[directml]==0.2.1 git clone https://github.com/microsoft/olive --branch v0.2.1 cd olive\examples\directml\stable_diffusion pip install -r requirements.txt pip install pydantic==1.10.12 3.生成ONNX模型并在运行时对其进行优化。这可能需要很长时间。 python stable_diffusion.py --optimize 优化后的模型将存储在以下目录中,保持打开状态以备以后使用:olive\examples\directml\stable_diffusion\models\optimized\runwayml.模型文件夹命名为“stable-diffusion-v1-5”。使用以下命令查看支持的其他模型:python stable_diffusion.py –help 测试优化后的模型 1.测试优化后的模型,执行如下命令: python stable_diffusion.py --interactive --num_images 2
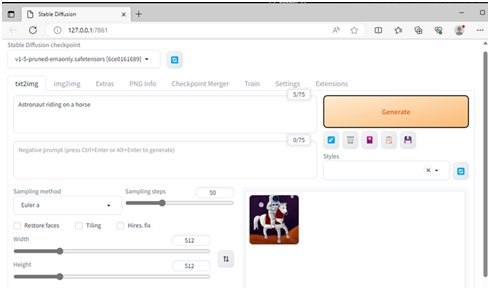
4.安装并运行Automatc1111Stable DiffusionWebUI 按照这里的说明,安装没有优化模型的Automatic1111Stable Diffusion WebUI。它将使用默认的未优化PyTorch路径。在新的终端窗口中依次输入以下命令。 1.打开Anaconda/Miniconda终端。 2.在终端中输入以下命令,然后输入回车键,以安装Automatc1111 WebUI conda create --name Automatic1111 python=3.10.6 conda activate Automatic1111 git clone https://github.com/lshqqytiger/stable-diffusion-webui-directml cd stable-diffusion-webui-directml git submodule update --init --recursive webui-user.bat 3.按住CTRL键并单击“Running on local URL:”之后的URL以运行WebUI
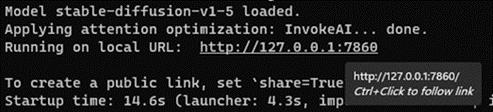
5. 在AMD Radeon上启用Olive优化路径 集成优化模型 将生成的优化模型(“stable-diffusion-v1-5”文件夹)从优化模型文件夹复制到目录stable-diffusion-web -directml\models\ONNX中。可能需要为某些用户创建ONNX文件夹。 使用优化模型运行Automatc1111 WebUI 1.启动一个新的Anaconda/Miniconda终端窗口 2.使用“webui.bat”进入目录,输入如下命令,以ONNX路径和DirectML方式运行WebUI。这将使用我们在第3节中创建的优化模型。 webui.bat --onnx --backend directml 3.按住CTRL键并单击“Running on local URL:”之后的URL以运行WebUI
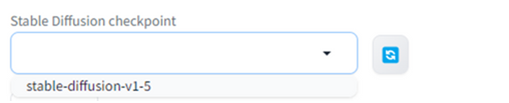
4. 从下拉列表中选择“stable-diffusion-v1-5”
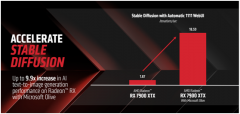
6.结论 AMD Radeon RX 7900 XTX在默认PyTorch路径上运行,每秒可提供1.87次迭代。 AMD Radeon RX 7900 XTX在Microsoft Olive的优化模型上运行,每秒可提供18.59次迭代。
最终结果是AMD RadeonRX 7900 XTX性能提升至高可达9.9倍。 |
| 编辑:乐小编 |

| 会展新闻 | ||||
| 推荐资讯 | ||||
|
||||
| 热门排行 | ||||